介绍
在深入解析RAG原理与实现一文中,我们探讨了如何构建RAG应用。然而,在成功构建RAG应用后,新的挑战随之而来:如何评估其性能?我们需要什么样的量化指标来进行有效的评估?
RAG评估
评估指标
在RAG流程中,主要包括三个核心部分:问题(Query)、检索到的文档(Context)以及模型生成的答案(Answer)。在评估过程中,我们还需要真实答案(Ground Truth)作为基准。在RAG应用中,我们关注两个关键点:其一是检索到的文档(Context),其二是基于检索到的文档所生成的答案(Answer)。下图1展示了这两个部分设置的评估指标,其中左侧列出了与Answer相关的指标,右侧则呈现了与Context相关的指标。指标计算方法可以参考RAGAS Metrics
Context
- Context Precision: 根据Context和Ground Truth计算检索到的Context准确率
- Context Recall: 根据Context和Ground Truth计算检索到的Context召回率
- Context Entities Recall: 根据Context和Ground Truth计算检索到的Context 中Entities的召回率
Answer
- Answer Faithfulness: 根据Context和Answer计算Answer是否来源于Context
- Answer Semantic Similarity: 根据Ground Truth和Answer计算Answer与Ground Truth的语义相似性(使用Embedding向量计算)
- Answer Correctness: 根据Ground Truth和Answer计算Answer准确率(使用LLM判断)
通过以上评估指标,我们能够更全面地评价RAG系统的性能。
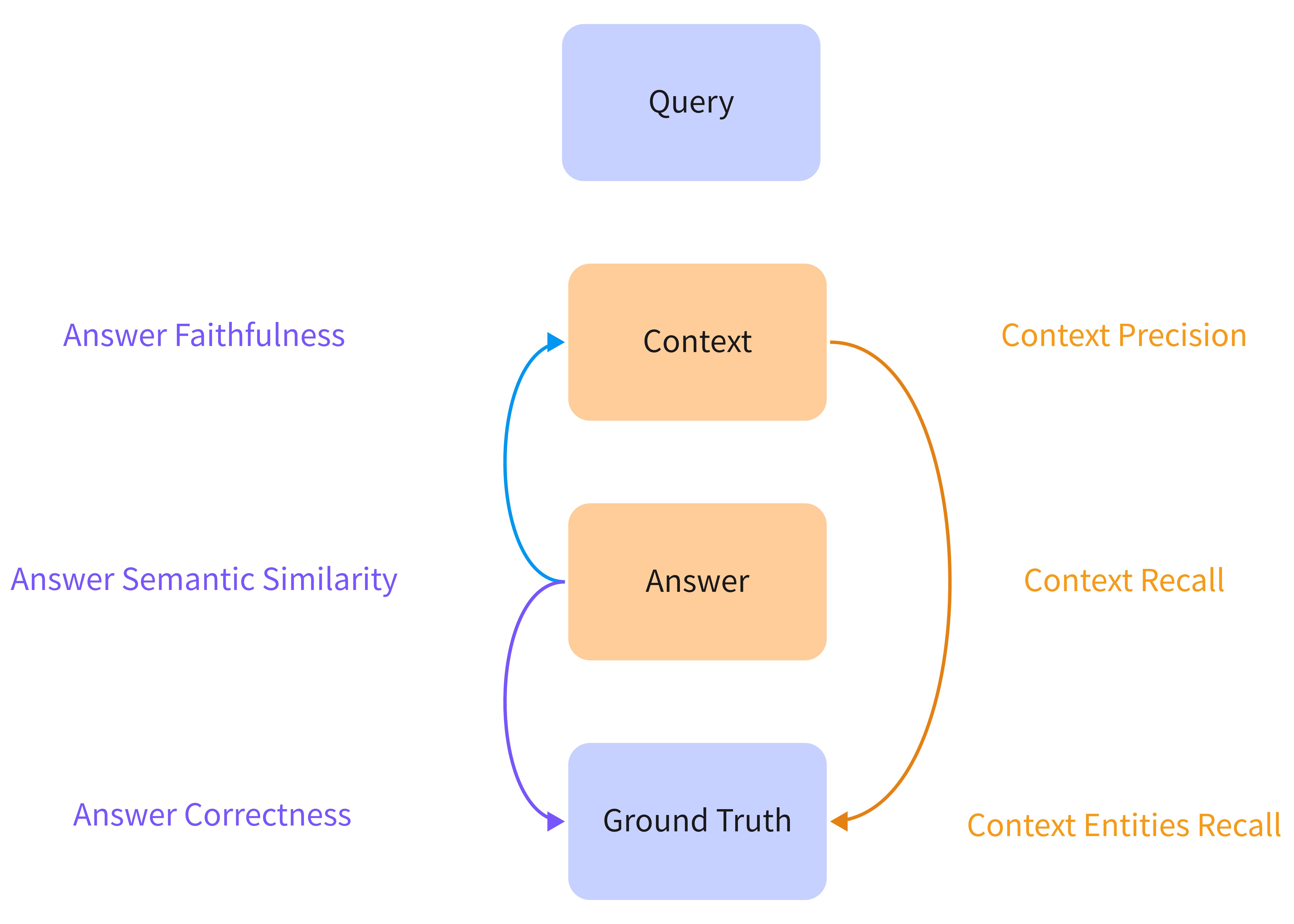
图 1. RAG 评估指标
计算方法
尽管大型语言模型(LLM)的上下文长度已显著增加,能够将整个文档甚至文本语料库纳入上下文窗口,但在实际应用中,这种做法往往效率低下,容易分散模型的注意力,同时也会增加推理延迟和成本。对于任何特定查询,仅有少量的文本可能具有相关性,但在每次推理时,上下文窗口中的所有token都需被处理。理想情况下,LLM 应该只处理与查询相关的token。因此,在检索增强生成(RAG)应用中,检索过程的主要目标便是精准识别并提取与给定查询相关的token。
Context Precison
Context Precision(上下文精度)是信息检索和问答系统中用来评估检索结果质量的重要指标之一。在检索过程中,系统可能会返回多个与用户查询相关的文档,这些文档的内容可能会对生成答案产生不同程度的影响。Context Precision的核心在于衡量在检索到的所有相关文档中,有多少文档实际上对生成用户需要的答案是有帮助的。
\[ Context\:Precision = \frac{有用的文档数量}{相关文档数量} \]- 相关文档数量 :指检索系统返回的所有相关文档的总数。
- 有用文档数量 :指在这些相关文档中,能够为生成正确答案提供有效信息的文档数量。
那么如何衡量文档对于答案生成是否有用呢?传统的NLP方法中可以使用EM算法,或者计算文档和答案之间词级匹配,这些方法仅计算词级别的重叠,忽略了语义上的近似表达。例如,“机器学习用于预测”与“模型被训练来预测”语义相近,但词汇不完全匹配,导致得分偏低。对于开放性问答任务,上下文和答案可能有多种合理表述,传统的机器学习方法无法处理这种问题。同时如果文档包含大量与问题无关的内容,只是偶尔提到了一些相关词汇,会导致误判。为了解决这些问题,可以使用基于大模型的计算方法,依赖于大模型的上下文学习以及推理能力进行判断文档对于答案生成是否有用,如:
| |
下面是对于衡量文档对于答案生成是否有用的Prompt示例,其中包含指令,格式化输出,示例和输入,通过这种设计方式可以让大模型生成格式化的评估结果。

图 2. Context Precision Prompt
因此Context Precision的计算过程如图3所示,首先是根据用户问题检索相关文档,对于每个文档使用图2中的Prompt输入到大模型中,获取大模型对于文档是否有用的判断,最终根据有用的文档数量计算Context Precision
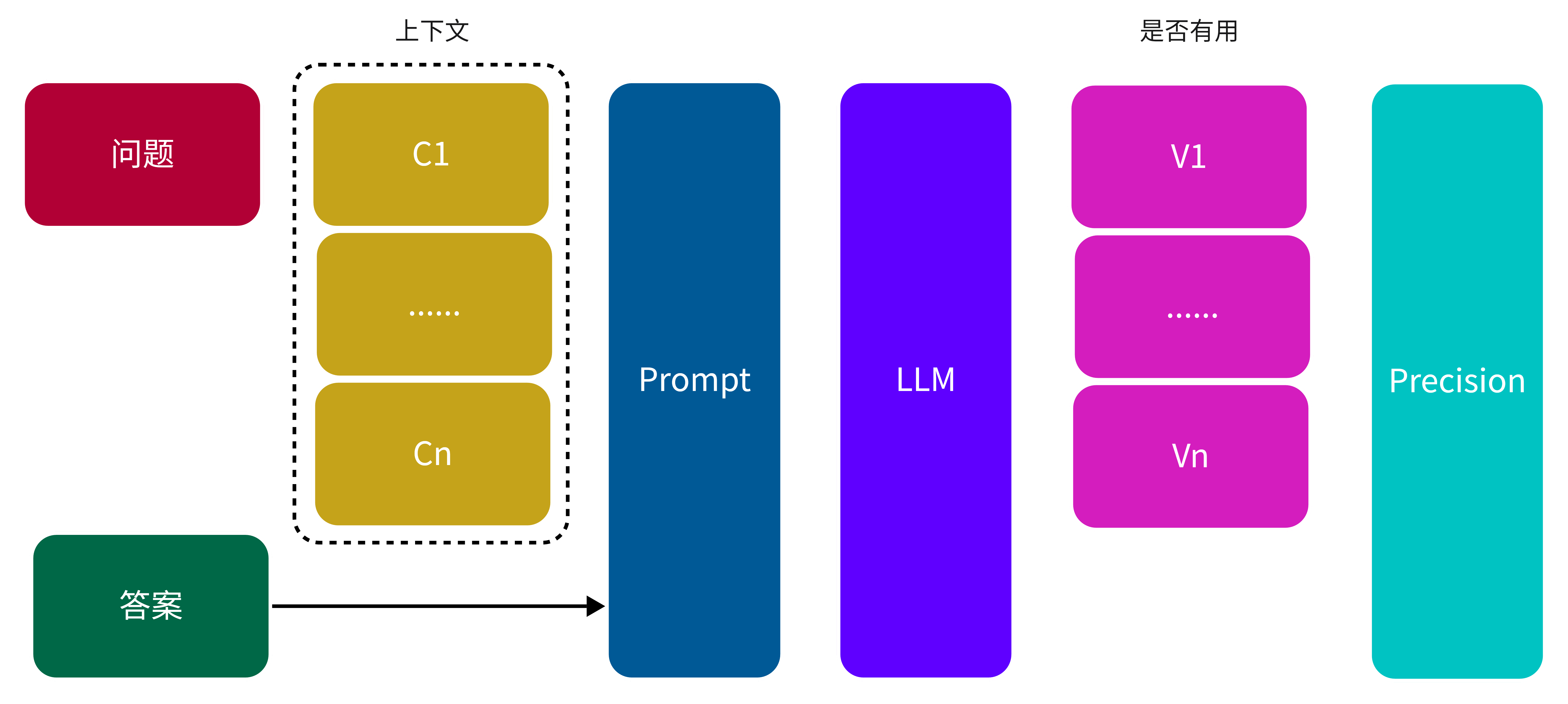
图 3. Context Precision 计算过程
| |
| |
Context Recall
Context Recall(上下文召回率) 是一种用于评估信息检索系统中检索结果覆盖程度的重要指标。它反映了系统在上下文中检索到的内容与预期信息(即 Ground Truth)之间的匹配程度。在开放问答系统中,Ground Truth 表示预期答案的完整内容或参考答案。Context Recall 的计算流程是通过将 Ground Truth 分解为多个独立的观点(statement),并判断这些句子是否能在检索到的上下文中找到对应内容。
Context Recall 的计算公式如下:
\[ Context\:Recall = \frac{上下文中存在的正确观点数量}{Ground Truth 的所有观点数量} \]- 上下文中存在的正确观点数量:在给定上下文中能够找到支持的观点的数量。
- Ground Truth 的所有观点数量:答案中涉及的所有观点的数量。
Prompt 示例

图 4. Context Recall Prompt
Context Recall 计算流程
| |
下图展示了 Context Recall 的计算过程:
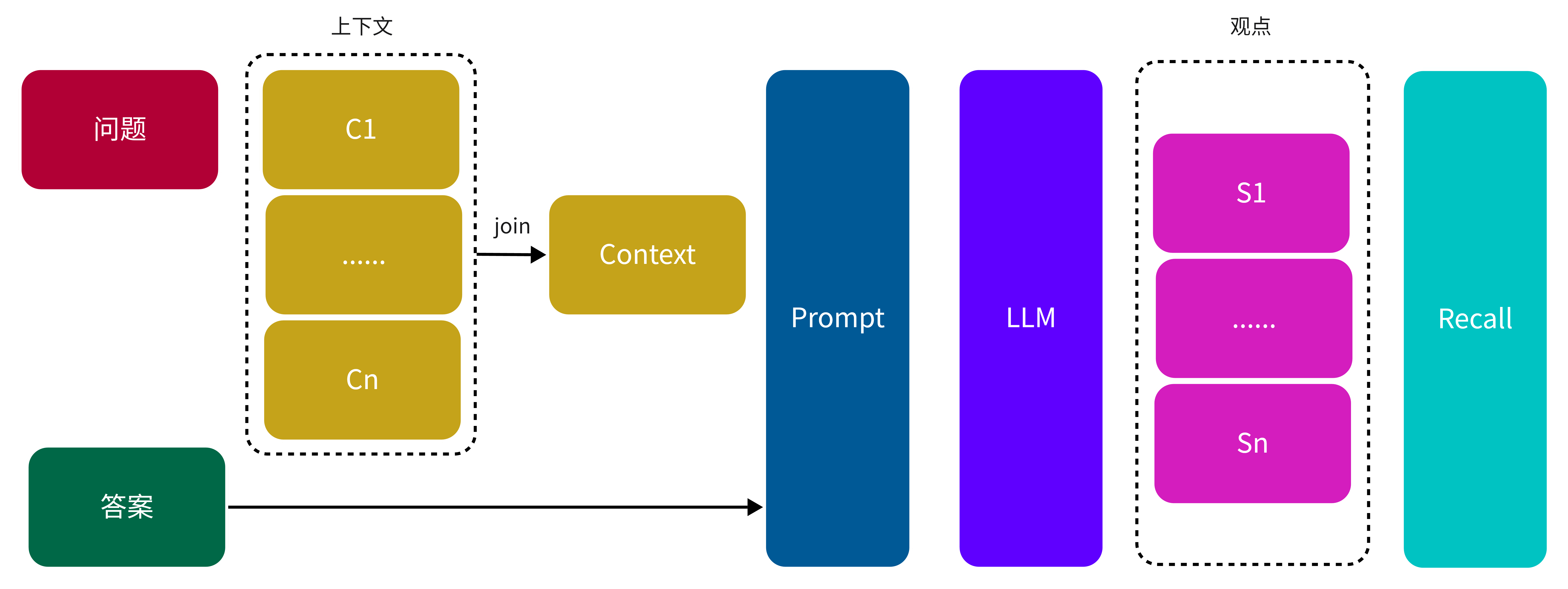
图 5. Context Recall 计算过程
| |
| |
Context Entities Recall
Context Entities Recall(上下文实体召回率)是一种用于评估检索过程的指标。它的核心思想是比较模型在给定上下文(Context)与真实答案(Ground Truth)中抽取到的实体,并计算Ground Truth中实体的召回率。该指标能够有效评估检索结果对于关键信息的召回率。
Context Entities Recall的计算公式为:
\[ Context\:Entities\:Recall = \frac{上下文中实体 \cap 真实答案中实体}{真实答案中实体} \]- 上下文中实体:检索到的上下文中实体集合
- 真实答案中实体:真实答案中实体集合
其中实体抽取主要是使用大模型进行解析,下面是实体抽取的Prompt

图 6. Context Entities Recall Prompt
下图展示了Context Entites Recall计算过程
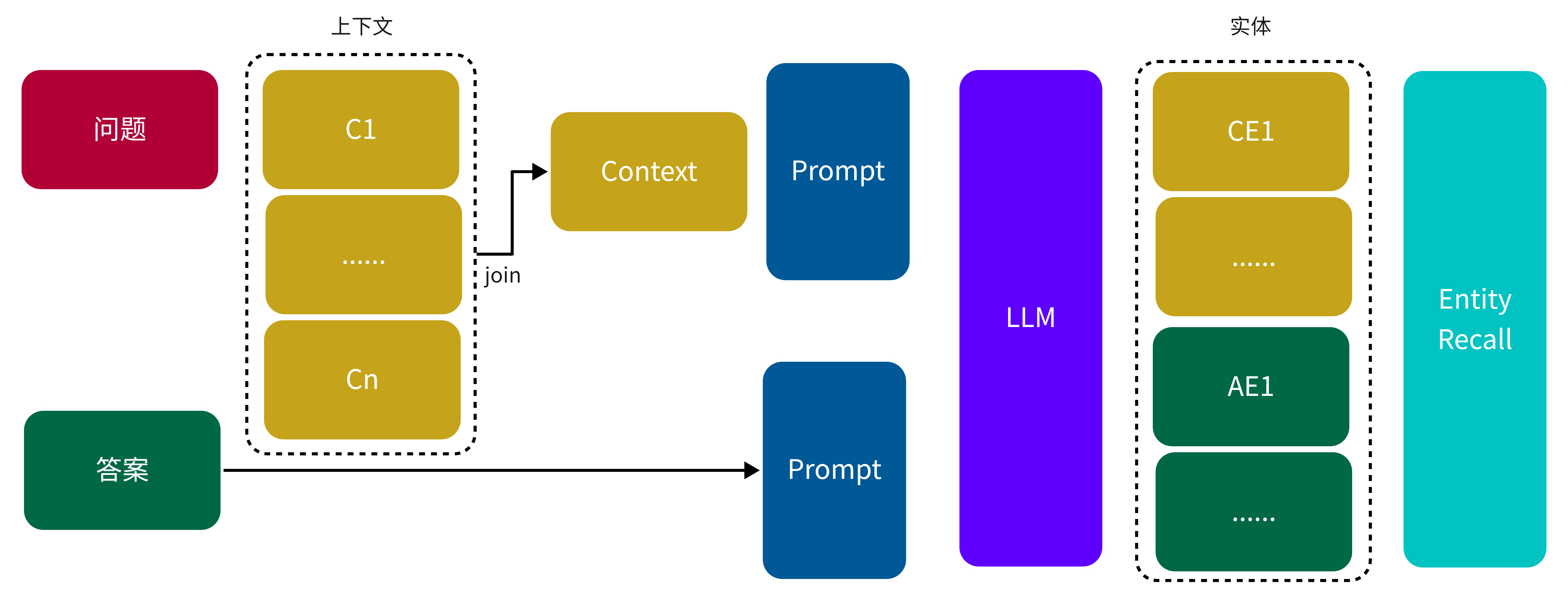
图 7. Context Entities Recall 计算过程
| |
| |
Answer Correctness
Answer Correctness(答案准确性) 是一种用于评估 RAG(Retrieval-Augmented Generation)应用生成的答案准确性的指标。其目标是衡量模型生成的答案与真实答案(Ground Truth)之间的匹配程度,从而判断模型是否生成了正确且有支持的内容。指标结合了经典的分类评价方法,将生成的答案分为正确识别(TP)、错误识别(FP)和遗漏(FN),帮助RAG应用回答的准确性。
- TP(True Positive,正确识别):
- 定义:答案中的语句与真实答案中的语句匹配,且得到了真实答案的明确支持。
- 作用:识别出模型正确生成的信息。
- FP(False Positive,错误识别):
- 定义:答案中出现了没有真实答案支持的语句,即错误信息或不相关内容。
- 作用:检测模型生成的无根据或错误信息。
- FN(False Negative,遗漏):
- 定义:真实答案中的语句未出现在生成的答案中,即模型漏掉的重要信息。
- 作用:评估模型在回答时是否遗漏了关键信息。
Answer Correctness 计算公式
\[ \text{Answer Correctness} = \frac{|\text{TP}|}{|\text{TP} + 0.5 * (\text{FP} + \text{FN})|} \]其中大模型分类的Prompt如下所示:

图 8. Answer Correctness Prompt
Answer Correctness 是一个加权的评估指标,同样的根据RAG应用回答分类也可以计算下面的几个指标:
精准率(Precision):反映生成的答案中,有多少比例是正确的内容。
\[ \text{Precision} = \frac{|\text{TP}|}{|\text{TP} + \text{FP}|} \]召回率(Recall):反映真实答案中的信息有多少被模型识别并生成。
\[ \text{Recall} = \frac{|\text{TP}|}{|\text{TP} + \text{FN}|} \]F1分数(F1 Score):结合了精准率和召回率的平衡指标,作为整体评价。
\[ F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} \]
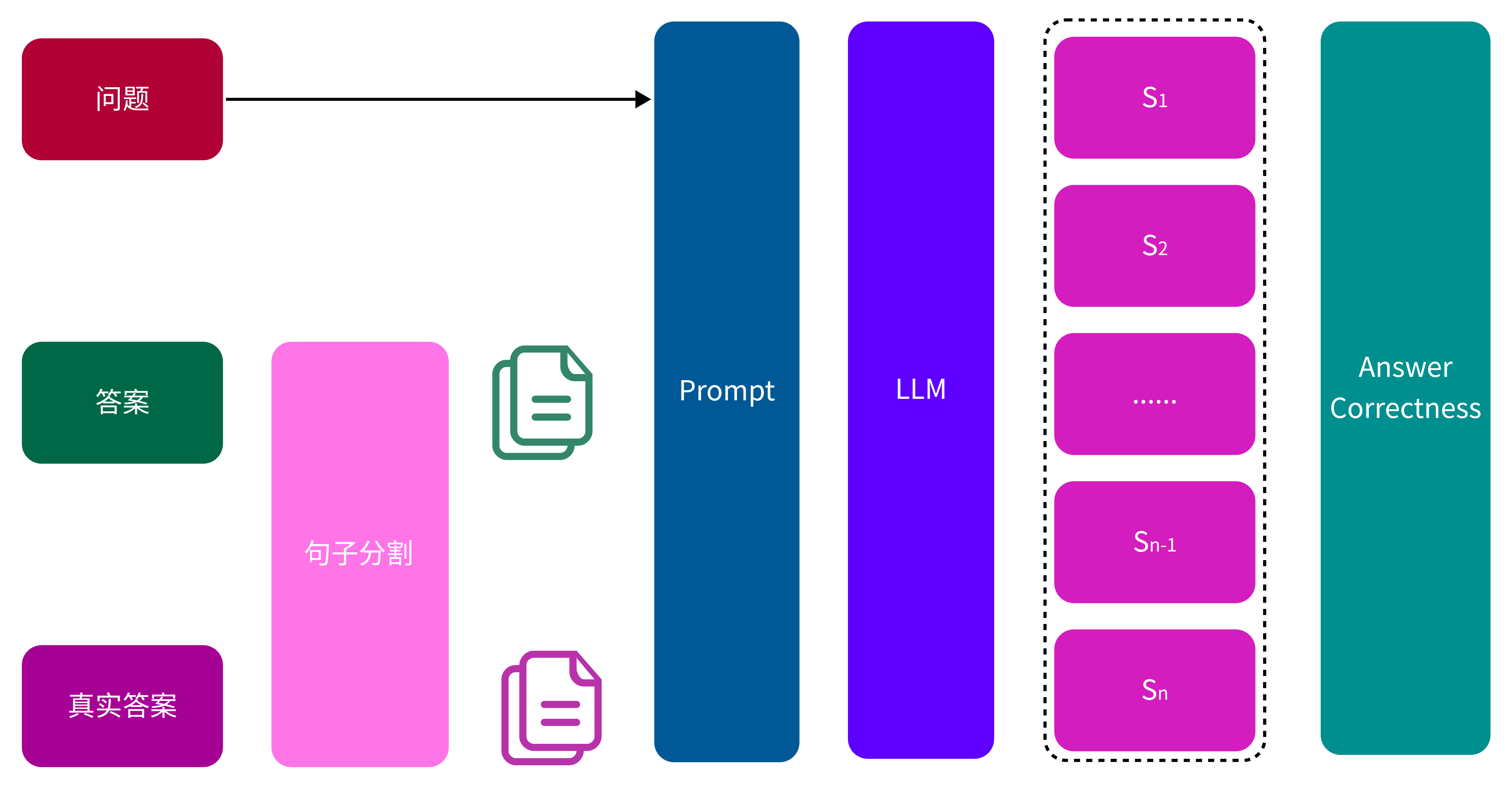
图 9. Answer Correctness 计算过程
| |
| |
Answer Semantic Similarity
Answer Semantic Similarity(答案的语义相似性)是用来评估生成答案与原始事实在语义上相近程度的关键指标。通过计算生成答案与基本事实的嵌入向量之间的余弦相似度,可以量化这种相似性。如果设定了一个特定的阈值,根据计算结果,得分会被转换为二进制值;即,当余弦相似度大于或等于该阈值时,值为1,否则为0。
\[ Answer\:Semantic\:Similarity = \cos(\hat{v}_{\text{answer}}, \hat{v}_{\text{fact}}) \]- \(\hat{v}_{\text{answer}}\):表示生成答案的嵌入向量。
- \(\hat{v}_{\text{fact}}\):表示基本事实的嵌入向量。
- 阈值:用于将相似度得分转换为二进制判断的临界值。
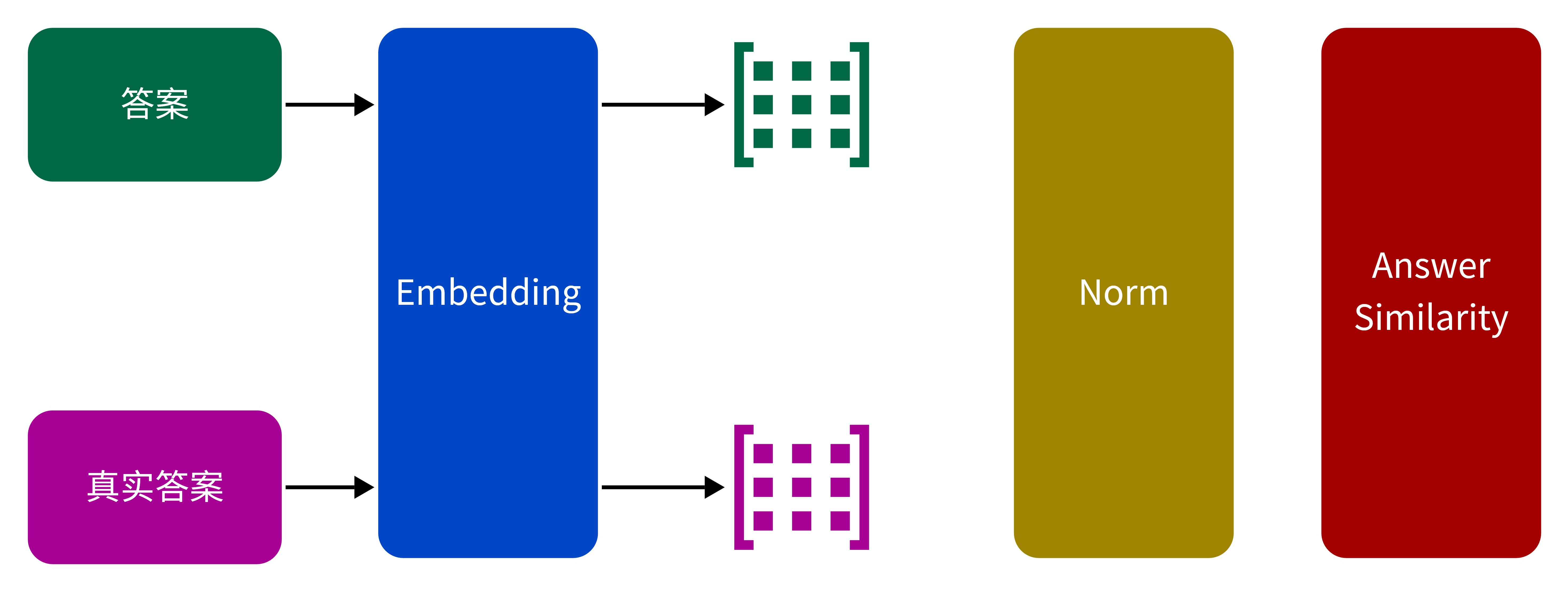
图 9. Answer Semantic Similarity 计算过程
| |
| |
Answer Fathfulness
Faithfulness(忠实性)指标用于衡量生成答案与给定上下文之间的事实一致性。该指标通过生成答案和检索到的上下文进行计算,其结果被缩放至 (0,1) 区间,数值越高表示忠实性越强。
如果生成的答案中所做出的所有陈述都能够从给定的上下文中推导出来,则视为忠实。在计算忠实性时,首先从生成的答案中识别出一组陈述,然后将每一个陈述与给定的上下文进行逐一核对,判断其是否可以从上下文中推导出来。忠实性得分的计算公式如下:
\[ Faithfulness score = \frac{可以推导出的陈述数量}{陈述总数量} \]- 可以推导出的陈述数量:指生成答案中,与给定上下文核对后确认可以推导出的陈述数量。
- 陈述总数量:指从生成的答案中识别出的全部陈述数量。
其中陈述总数量是通过大模型进行拆分,下面是根据RAG输出的答案生成陈述的Prompt

图 10. Answer To Statements Prompt
可以推导出的陈述数量也是通过大模型进行判断,根据上述过程生成的陈述以及检索到的上下文,判断模型生成的答案是否可以在上下文中找到依据,下面给定上下文判断是否可以推导出的陈述的Prompt

图 11. Answer Statements Fathfulness Prompt
下面是Answer Fathfulness的计算过程
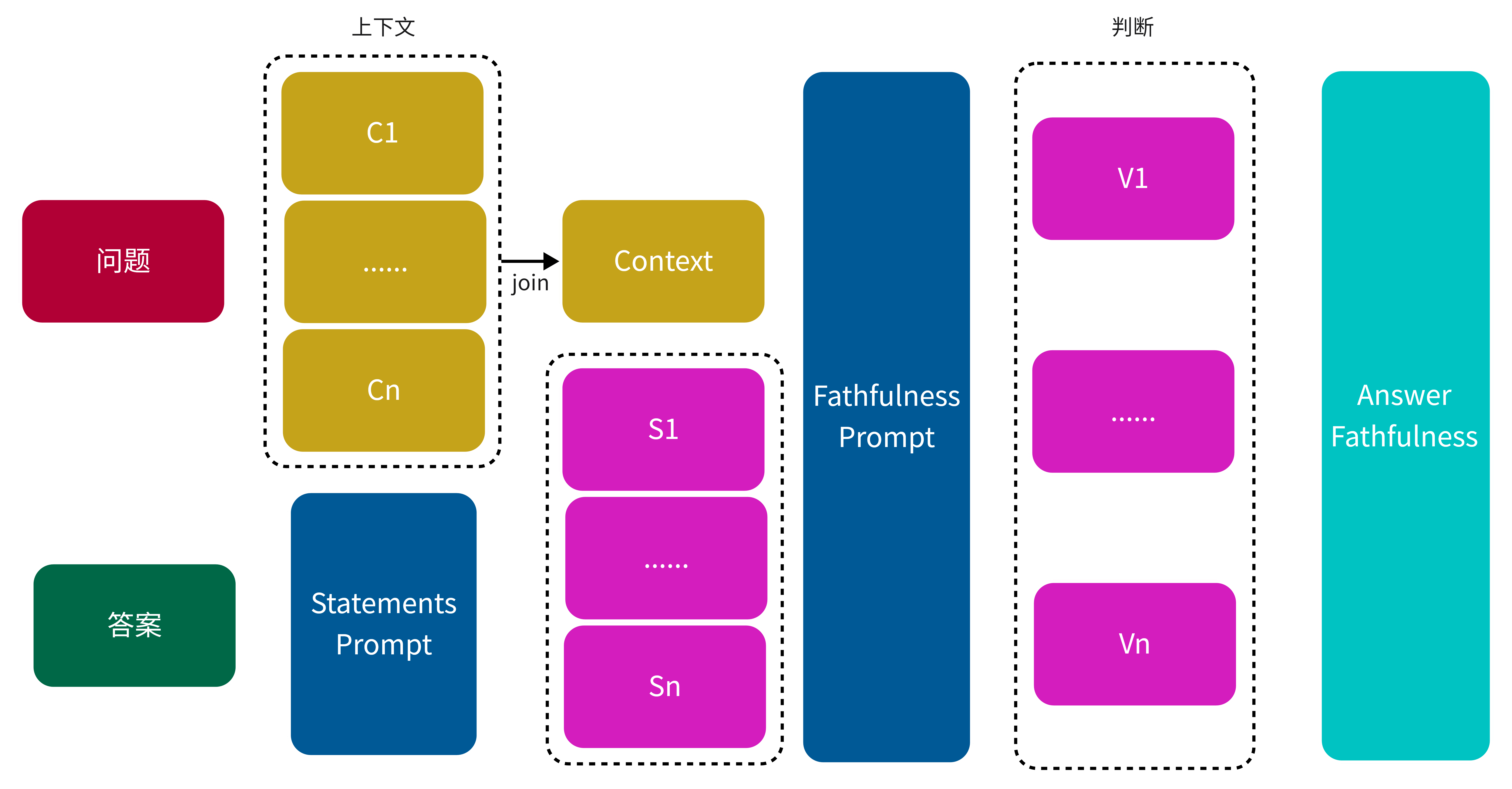
图 12. Answer Fathfulness 计算过程
| |
| |
讨论
在本文中,我们探讨了基于大型语言模型的RAG应用自动化评估方法,并详细阐述了每个评估指标的提示设计及其Python实现方式。通过本篇文章,我们不仅理解了如何利用大型语言模型进行评估,还可以根据自身的业务场景制定相应的评估指标。
值得注意的是,在上述评估指标的计算过程中,我们使用了几个关键要素,即Query、Context、Answer和Ground Truth。其中,Query、Context和Answer是RAG应用的输入、中间变量和生成结果,这些要素相对容易获取。然而,获取Ground Truth通常较为困难。在一般情况下,Ground Truth可通过人工或专家标注获得,但这种方法往往需要大量的人力资源。
如果我们能够解决自动生成Ground Truth的过程,那么整个评估流程将会实现自动化。在下一篇文章中,我们将深入探讨如何基于文档自动生成高质量的问答数据。
引用
- Yu H, Gan A, Zhang K, et al. Evaluation of Retrieval-Augmented Generation: A Survey[J]. arXiv preprint arXiv:2405.07437, 2024.
- https://research.trychroma.com/evaluating-chunking
- https://github.com/explodinggradients/ragas